Performance Portability Analysis
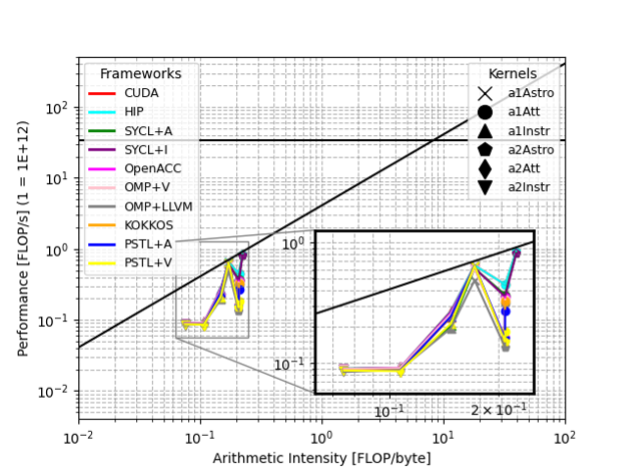
Modern scientific software requires ever-increasing computing capacity, necessitating increasingly specialized systems to run on purpose-built supercomputers. Given that each supercomputer is generally a one-off project, the need for computing frameworks portable across different CPU and GPU architectures without performance losses is increasingly compelling. Pennycook’s portability score allows for quantifying how performance varies across HW platforms. We use it to study the properties of different HPC programs, for example, the solver module of the AVU-GSR pipeline for the ESA Gaia mission. This code finds the astrometric parameters of 108 stars in the Milky Way using the LSQR iterative algorithm. Besides its astrophysical relevance, LSQR is widely used to solve linear systems of equations across a wide range of high-performance computing applications. We optimized the previous CUDA implementation and ported the code to further six GPU-acceleration frameworks: C++ PSTL, SYCL, OpenMP, HIP, KOKKOS, and OpenACC. Thanks to the great availability of heterogeneous resources on HPC4AI, we evaluated each framework’s performance portability in terms of application and architectural efficiency across different GPUs. Specifically, we use NVIDIA T4, V100, A100, and the new GH200. For each GPU, we compute the roofline model to get the architectural efficiency.
Contacts:
Contact: Giulio Malenza