xFFL: cross-Facility Federated Learning


For more research from our group, visit the official website of Parallel Computing [ALPHA]



Research Objectives
Cross-Facility Federated Learning (xFFL) is an experimental distributed computing methodology designed to explore three main research directions:
- Using High Performance Computers (HPCs) as an enabling platform to train and fine-tune foundational AI models;
- Exploiting the aggregated computing power of multiple HPCs simultaneously through a Workflow Management System (WMS) to solve today’s large-scale problems (e.g., training trillion-parameters models);
- Federated Learning (FL) as a technique for virtually pooling different datasets while keeping each one private to its owner(s).
To our knowledge, xFFL is the first experimental attempt to train a foundational model (e.g. META’s LLaMA) through a cross-facility approach on geographically distant HPCs exploiting WMS and FL techniques to coordinate the distributed learning.
Methods and Tools
The xFFL experiments presented below are based on a previous small-scale experiment entitled “Federated Learning meets HPC and cloud” [1], which describes the federated training of a VGG16 model across the Marconi100 supercomputer (CINECA, located in Bologna, Italy) and the HPC4AI OpenStack cloud (UniTo, located in Turin, Italy). The two infrastructures are given two different datasets, as standard practice in an FL context: MNIST on Marconi100 and SVHN on HPC4AI. This experiment shows that not only is it possible to train a Deep Neural Network (DNN) on two different computing infrastructures through an FL approach, but also that is possible to exploit two different computing paradigms (i.e., HPC and cloud) at the same time is their pros and cons are handled correctly.
The presented approach is general enough to be reused in the xFFL experiments on a larger scale. This is possible thanks to the flexibility offered by the StreamFlow WMS, which can exploit much larger networks than two computing infrastructures. The workflow used in the large-scale xFFL experiments is a straightforward extension of the one proposed in [1]. However, this does not imply that the two experiments exhibit the same deployment complexity. Scalability is no free lunch in nature, and the xFFL experiments themselves are designed to study scalability and deployment problems of contemporary AI models on HPCs to distil a methodology to make such large-scale training of foundational models scalable across one or more HPCs.
META’s LLaMA models’ family is adopted to represent contemporary large-scale AI models. During the various iterations of the xFFL experiments, both LLaMA 2 – 7 billion and LLaMA 3 – 8 billion are used. Both models are always trained from scratch, a task that the Large Language Model (LLM) community calls pre-training: the models’ weights are initialised at the beginning of the training process, and all the models’ parameters are trained in full precision. No quantisation or parameters’ subset selection is employed. PyTorch’s Fully Shared Data Parallelism (FSDP) is exploited for the single-infrastructure distributed training, exploiting both model and data parallelism simultaneously. Model parallelism is used to fit the model in memory since it exceeds the capacity of any modern GPU; it is mainly applied across GPUs of the same node (e.g., 4xNVIDIA A100 64GB), whereas data parallelism (in a distributed learning fashion) is mostly exploited across different nodes to reduce training time (via NVIDIA NCCL).
Federated Learning
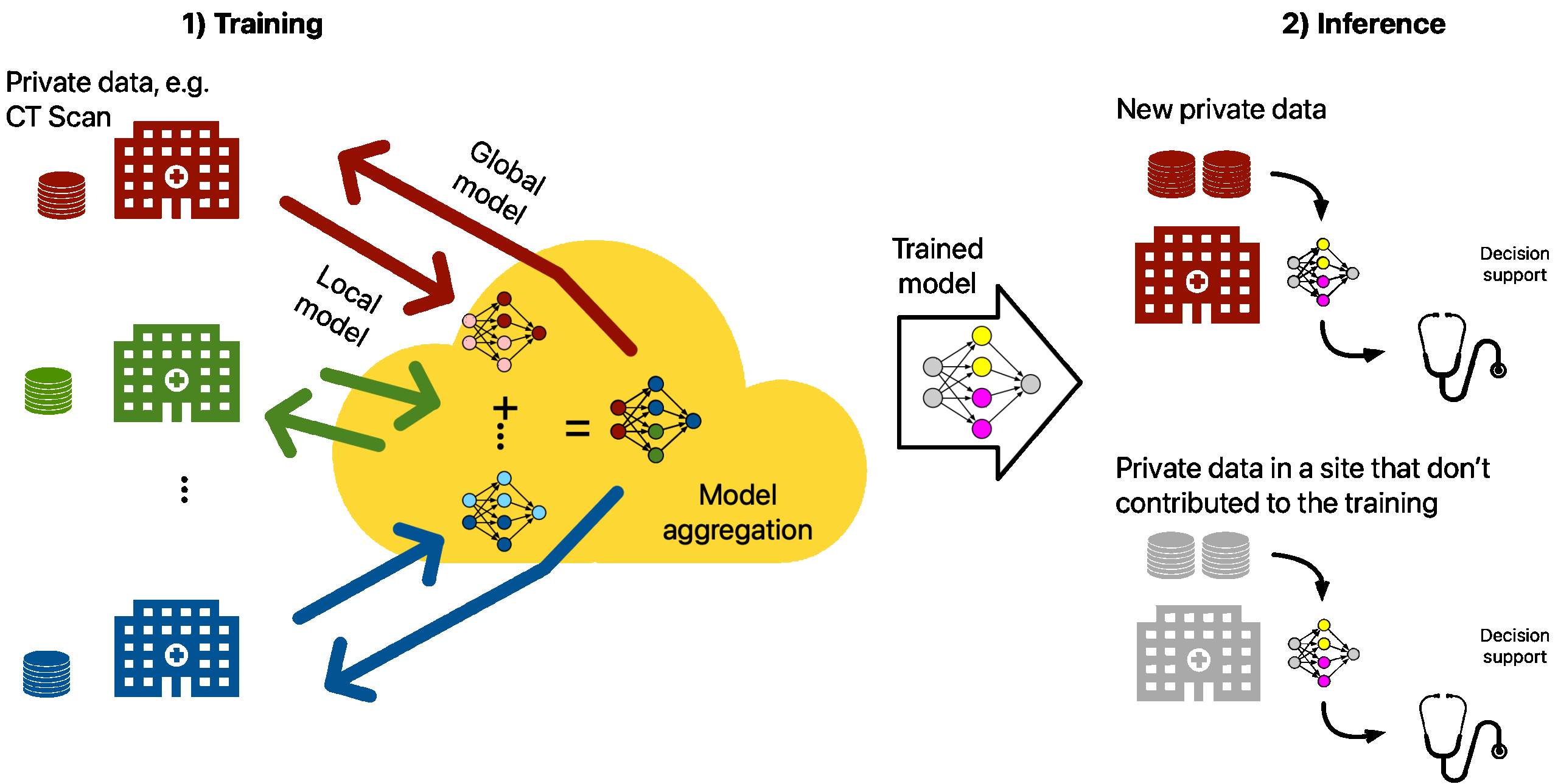
Recent years have been characterized by crucial advances in AI systems. The ubiquitous availability of datasets and processing elements supported these advances. The consequent deployment of ML methods throughout many industries has been a welcome innovation, albeit one that generated newfound concerns across multiple dimensions, such as performance, energy efficiency, privacy, criticality, and security. Concerns about data access and movement are particularly felt by industrial sectors such as healthcare, defence, finance, and any other sector treating sensitive data.
Federated Learning (FL) is a learning paradigm where multiple parties (clients) collaborate to solve a common learning task using their private data. Each client’s local data never leaves the client’s systems since clients collaborate by exchanging local models instead of moving the data in its most common configuration. The aggregator collects and aggregates the local models to produce a global model. The global model is then sent back to the clients, who use it to update their local models. Then, using their private data, they further update the local model. This process is repeated until the global model converges to a satisfactory solution or a maximum number of rounds.
FL initially targeted only DNNs due to their inherent simplicity of aggregation. Different instances of the same model are representable as tensors, and the most straightforward method to aggregate different tensors is to calculate their average. This is Federated Average, the first and most simple aggregation strategy used in FL. Nonetheless, FL research constantly pushes the boundaries of standard FL practice, trying, for example, to apply the FL methodology on non-DNN-like models [2] or to go beyond the standard client-server architecture implied in standard FL [3].
StreamFlow
The StreamFlow framework is a container-native Workflow Management System (WMS) written in Python3 and based on the Common Workflow Language (CWL) open standard [4-6]. Developed and maintained by the Parallel Computing [ALPHA] research group at Università di Torino (UniTO), it is designed around two main principles:
- Allowing the execution of workflows in multi-container environments to support the concurrent execution of multiple communicating steps across distributed heterogeneous infrastructures, such as supercomputers, clouds, private clusters, and even laptops;
- Realising complete separation of concerns between workflow business logic (steps and their data dependencies) and deployment plan. The same workflow can be deployed in a different platform or set of platforms by changing only the deployment plan of workflow steps while maintaining the business logic unchanged. Deployment modules can be plugged in to extend the default methods SLURM, PBS, LFS, K8S, AWS, OpenStack, SSH, etc.
Furthermore, collective operators (scatter, gather) and cyclic workflows are first-class concepts in CWL and StreamFlow, allowing for a broader and more powerful workflow design. Also, thanks to the CAPIO backend, streaming across successive workflow steps can be introduced, automatically optimising data transfer operations. Finally, relaxing the requirement of a single shared data space allows hybrid workflow executions on top of multi-cloud or hybrid cloud/HPC infrastructures.
StreamFlow source code is available on GitHub under the LGPLv3 license. A Python package is downloadable from PyPI, and Docker containers can be found on Docker Hub.
The Large Language Model Meta AI (LLaMA)
Over the last year, Large Language Models (LLMs) — Natural Language Processing (NLP) systems with billions of parameters — have shown new capabilities to generate creative text, solve mathematical theorems, predict protein structures, answer reading comprehension questions, and more. They are one of the most transparent cases of the substantial potential benefits AI can offer at scale to billions of people. Even with all the recent LLM advancements, full research access to them remains limited due to the required resources to train and run such large models. This compute divide has limited researchers’ ability to understand how and why these large language models work, hindering the efforts to improve their robustness and mitigate known issues, such as bias, toxicity, and the potential for generating misinformation [7].
META publicly released the first version of LLaMA (Large Language Model Meta AI) in February 2023, a state-of-the-art foundational LLM designed to help researchers advance their work in this subfield of AI. Different LLaMA versions are distributed according to the targeted task (e.g., chat or code) and the model’s size. LLaMA-2, released in July 2023, is an updated version of LLaMA pre-trained on a new corpus of mixed publicly available data increased by 40% compared to the previous version, with a doubled context length and grouped-query attention. LLaMA-2 is released with 7, 13, and 70 billion parameter versions [7,8]. LLaMA-3, released in April 2024, is the latest iteration of LLaMA. It is pre-trained on approximately 15 trillion tokens gathered from publicly available sources and, at the time of writing, is released in the 8 and 70 billion parameter versions, even if a 400 billion version is announced to be released.
xFFL – First Iteration (Winter 2023) [9]
The first iteration of the xFFL experiment aims to train the LLaMA-2 7 billion model exploiting two EuroHPC supercomputers cooperatively: Leonardo (CINECA, Bologna, Italy) and Karolina (IT4Innovations, Ostrava, Czech Republic). Since those two infrastructures are located in two states speaking different languages, such an experiment aims to train a single bilingual model through FL using two distinct language corpora, which are kept private at each site:
- The Italian Clean Common Crawl’s web crawl corpus (clean_mc4_it – 102GB – 20G tokens), which is kept private in Italy within Leonardo storage;
- The Czech Common Crawl’s web crawl corpus (mc4_cs – 169GB – 20G tokens), which is kept private in the Czech Republic within Karolina storage.
The xFFL code produced for this setup is open source and includes reproducibility scripts. Visit the official xFFL GitHub page for more information. Also, these results have been published in the Proceedings of the First EuroHPC User Day under a Creative Commons license. If you want to cite xFFL, please refer to this article:
I. Colonnelli, R. Birke, G. Malenza, G. Mittone, A. Mulone, J. Galjaard, L. Y. Chen, S. Bassini, G. Scipione, J. Martinovič, V. Vondrák, M. Aldinucci, “Cross-Facility Federated Learning,” in Procedia Computer Science, vol. 240, p. 3-12, 2024. doi: 10.1016/j.procs.2024.07.003.
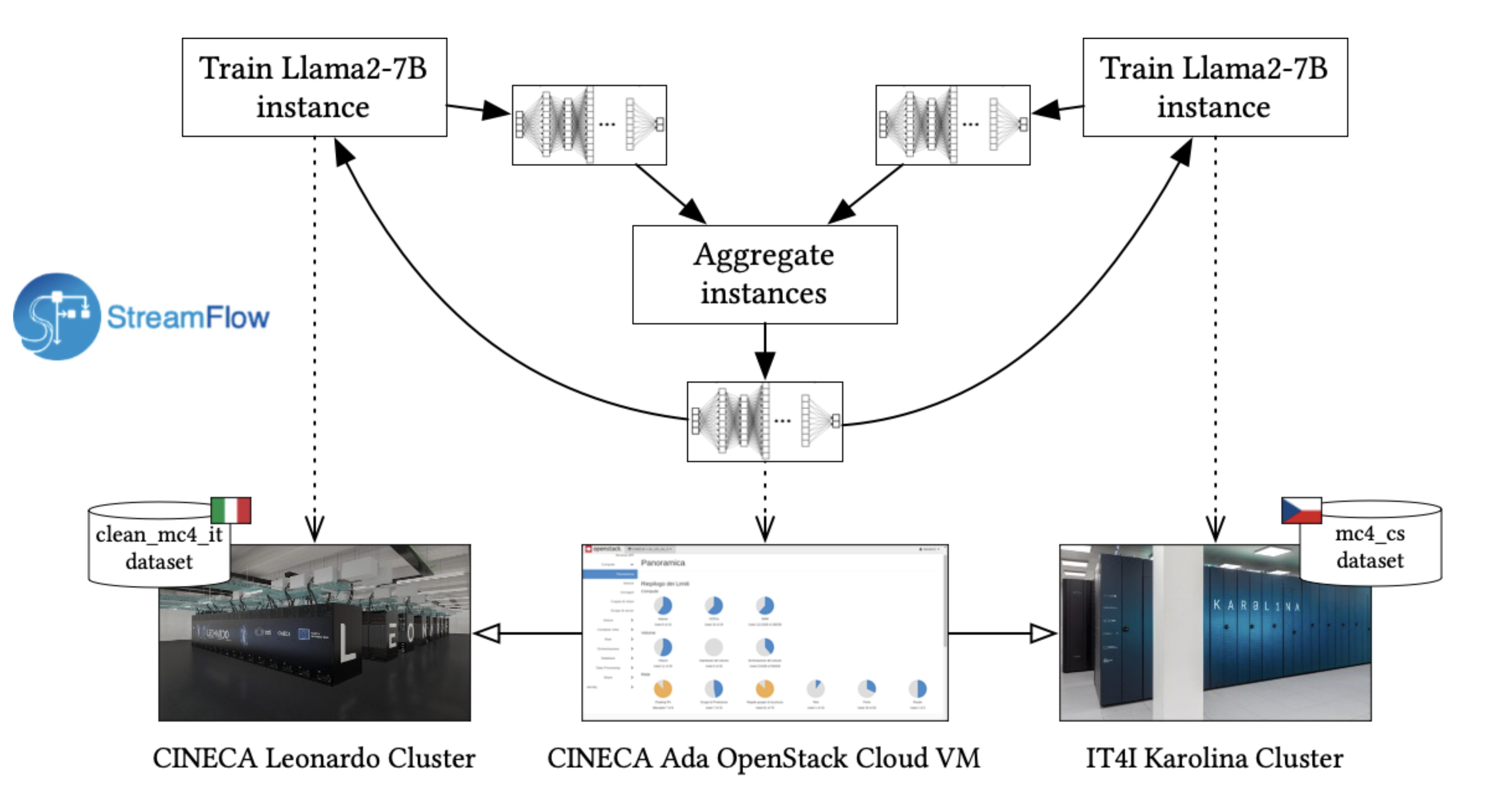
The FL protocol is described by a cyclic workflow expressed through CWL and executed by the Streamflow WMS, which supports distributed cloud-HPC workflow deployments. The xFFL workflow execution is managed by a Streamflow orchestrator running on a cloud VM: it produces SLURM jobs with input data (aggregated LLaMA model) to be submitted to the different supercomputers and gathers the jobs’ results (a set of LLaMA models, each trained on a different supercomputer) for the aggregation step. Training and validation datasets remain stored on the owner’s infrastructures and never move.
Performance
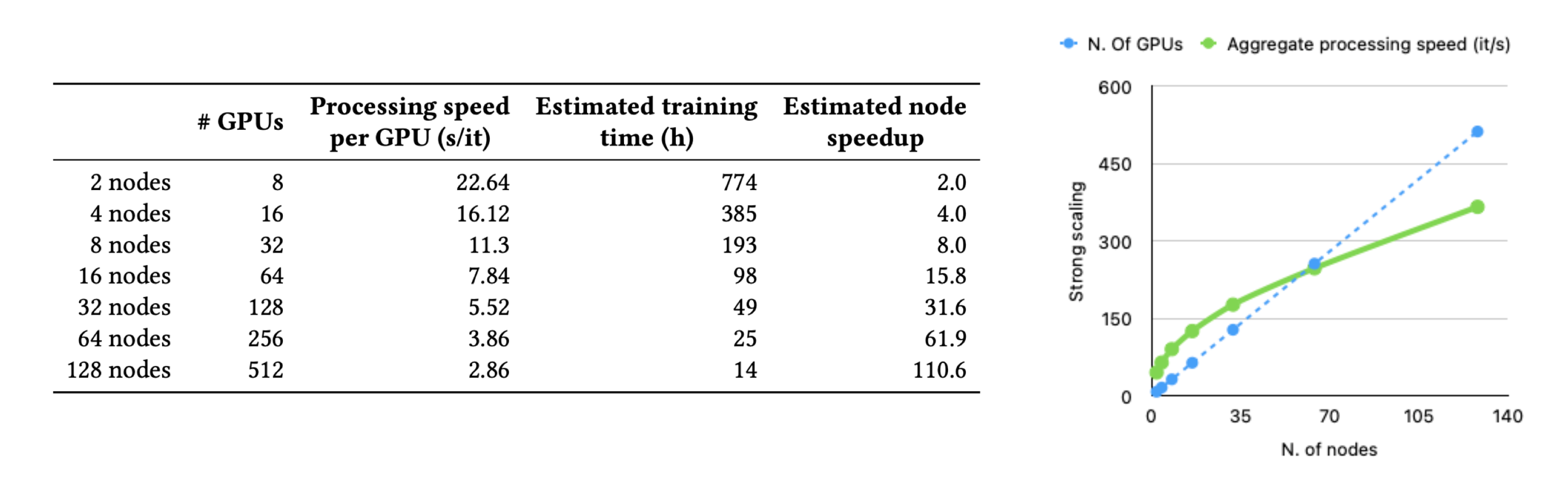
A single supercomputer (Leonardo) distributed training benchmark is reported below. Note that each Leonardo node is equipped with 1 x CPU Intel Xeon 8358 32 core, 2.6 GHz, 512 (8 x 64) GB RAM DDR4 3200 MHz, 4 x GPU NVidia A100 SXM6 64GB HBM2 and 2 x Card NVidia HDR 2×100 Gb/s. As can be seen, the scaling performance of PyTorch’s FSDP is solid until 64 computing nodes and starts to spoil after that scale.
Scalability in a federated execution is hard to achieve: in addition to the overheads of distributed training on a single supercomputer, FL exhibits several other sources of potential overheads. At each round:
- Model exchange time across a geographical-scale network;
- Aggregation time (either centralized or distributed);
- Load imbalance between different sites due to different dataset sizes and/or different computing power;
- Job queue waiting time (typically the main performance issue due to the inherent stochasticity of this time span).

Limitations
Notice that the two corpora are public and not massive data sets. Theoretically, they can be moved to a single supercomputer to exploit a traditional single-site distributed training of the LLaMA model. Nevertheless, this use case represents a paradigmatic example of the FL privacy-preserving properties or fine-tuning of a foundational model starting from a distributed pool of private datasets, each resident in a different site.
The LLaMA-2 model is available in several sizes (7B, 13B, 33B, and 65B parameters). The LLaMA-2 7 billion parameter version is adopted in this setting due to experimental resource reasons; the larger versions require more experimentation time and/or GPUs (that, in turn, increase the job waiting time in the submission queue).
Lesson Learned
Modern AI depends on pre-trained models, which evolve very rapidly. The latest LLaMA-2 model can be trained only using the nightly build of PyTorch at the time of experimenting: supercomputer users will likely be required to rebuild their tools and libraries frequently.
HPC federations that pass through standard workload managers (batch job queues) require “some” synchronization between different supercomputers, e.g., using the BookedSLURM extension (that leverages advanced reservation).
Two-factor authentication to access supercomputers needs to be automatized for distributed workflow execution. The synchronization across different infrastructures should not depend on mobile phone authentication.
xFFL – Second Iteration (Spring 2024)
The second iteration of the xFFL experiment focuses more on broadening the distributed computation scale, targeting a more realistic use case. This time, LLaMA-3 8 billion is trained using a prompt-tuning approach for an open-ended generation task on three EuroHPC supercomputers: Leonardo (CINECA, Bologna, Italy), LUMI (CSC, Kajaani, Finland), and MeluXina (LuxProvide, Bissen, Luxembourg). The dataset used is again the clean_mc4_it dataset. Data is fed to the LLM with a generic prompt ( “Scrivi un documento” – “Write a document”), and the perplexity between the generated text and the document passed on the template is calculated. Aggregation happens on a VM hosted by CINECA Ada cloud in Bologna also in this second setting.
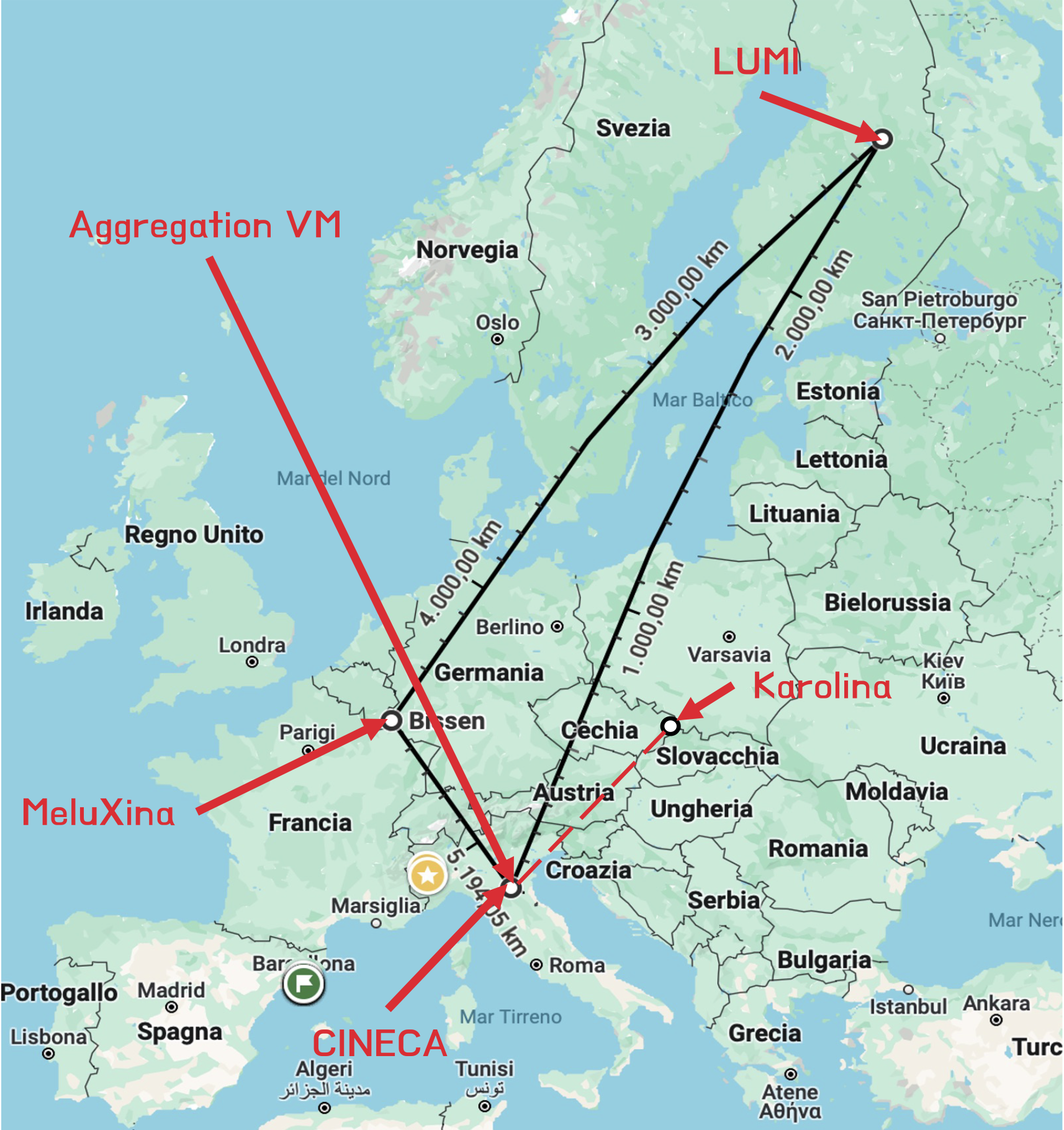
The first “true” European HPC federation?
The cooperation between Leonardo, MeluXina, and LUMI requires data to be exchanged across a total of 5.194 km (much more than the 782 km between Bologna and Ostrava). The total land surface covered by the three HPCs is 679.805 km2, ~16% of the EU surface area. These geographical distances play a fundamental role in the distributed communications: minimizing data transfer time is mandatory.
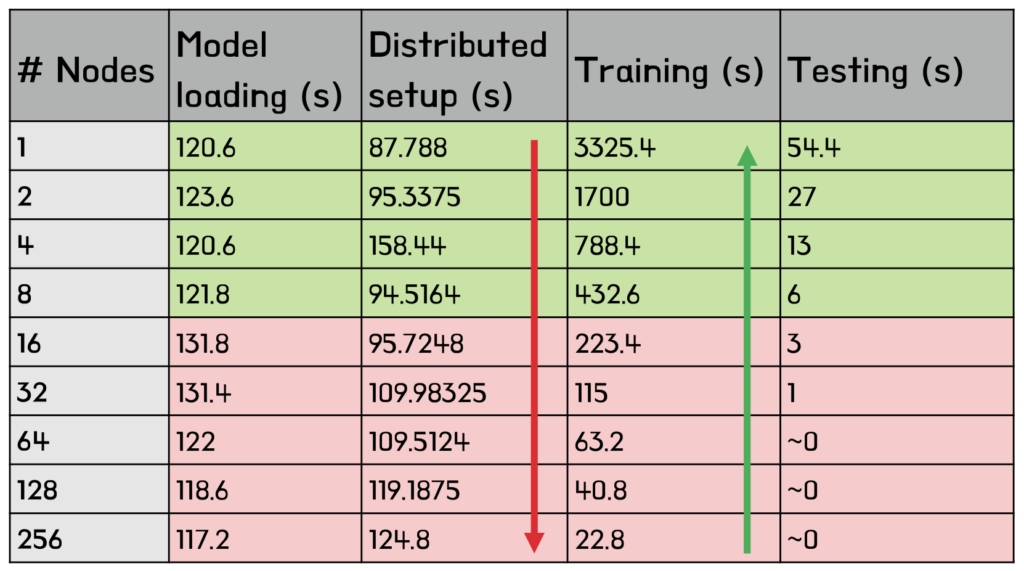
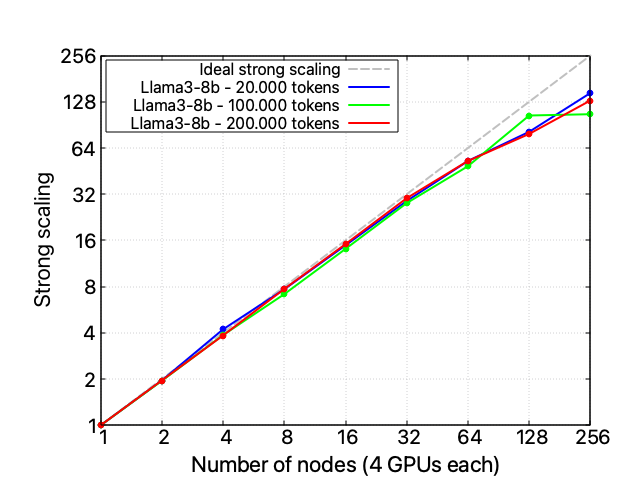
Before analysing the xFFL performance results in this setting, it is necessary to investigate the performance of each computing infrastructure available for AI-based tasks. The following presents performance results obtained training LLaMA-3 8 billion parameters on 20.000 training tokens (clean_mc4_it tiny has 4.085.342 tokens total) on Leonardo.
The first thing to be noticed is the code’s relatively poor scalability performance: the setup overhead becomes predominant starting from 16 nodes (64 GPUs). The training itself, on the other hand, seems to scale reasonably well.
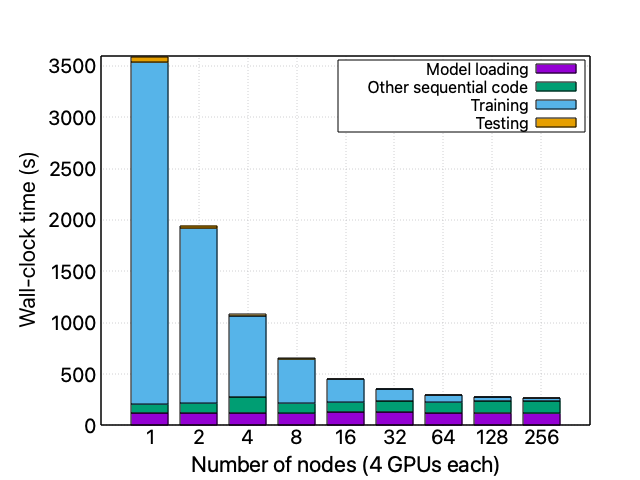
A more in-depth scalability analysis on Leonardo
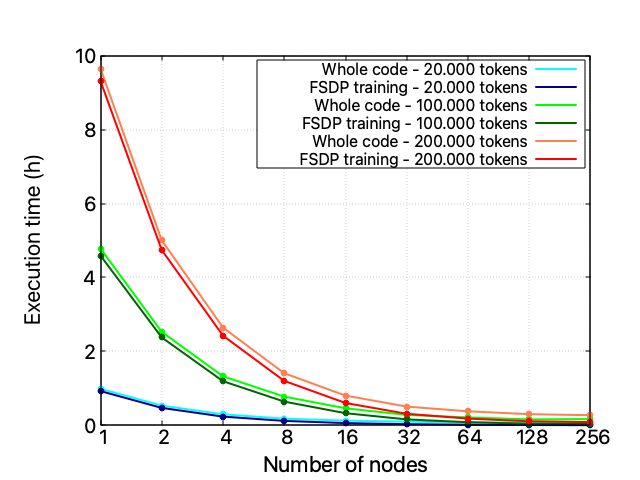
These performance issues do not seem to be correlated with the problem’s size (i.e., the size of the training dataset) or related to the FSDP distributed training technique. These statements are confirmed by the fact that increasing the training dataset size does not change the code’s scaling behavior and that isolating the performance of the FSDP code section ensures its nice scalability performance up to 128 nodes.
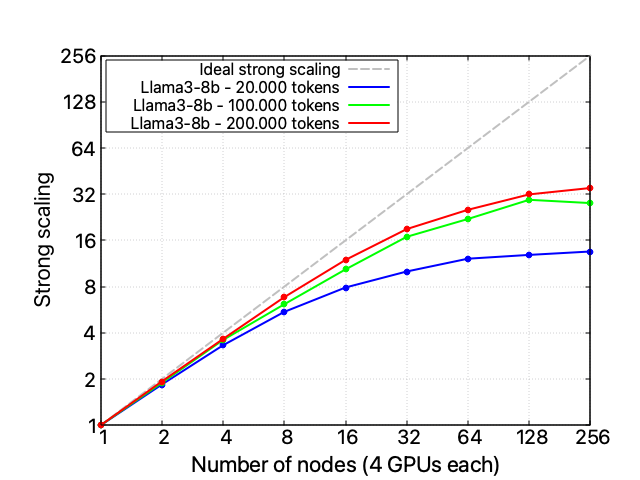
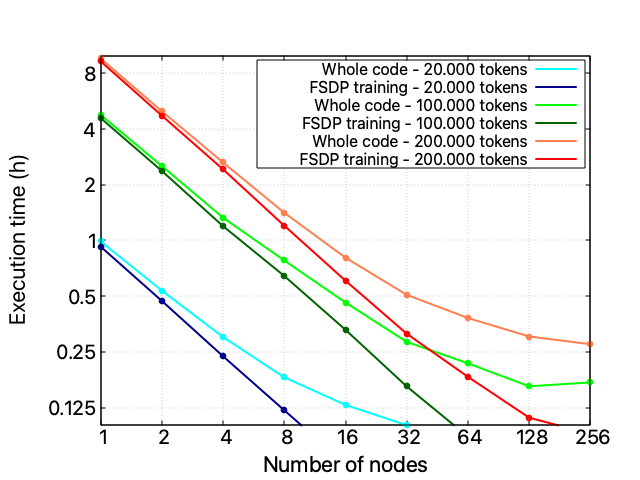
A three-HPC scalability analysis
When investigating this performance issue and comparing all three available HPC infrastructures, it appears clear that the problem is unrelated to the hardware itself: also on LUMI and MeluXina the whole code’s scalability performance starts to spoil after 16 nodes, while the FSDP component scales reasonably well on all infrastructures. Take into account that each LUMI node exposes a 1 x CPU AMD EPYC 7A53 “Trento” 64-core, 512 (8×64) GB DDR4 RAM4 x GPU AMD MI250X, 128 GB (64×2) HBM2e, and an HPE Cray Slingshot-11 – 1 x 200 Gb/s, while MeluXina a 2 x CPU AMD EPYC Rome 7452 32 core, 2.35 GHz, 512 GB RAM, 4 x GPU NVIDIA A100 40GB, and 2 x HDR200 SP, dual-rail. A single instance of LLaMA-3 8 billion can fit into a single Leonardo or LUMI node but requires two nodes on MeluXina.
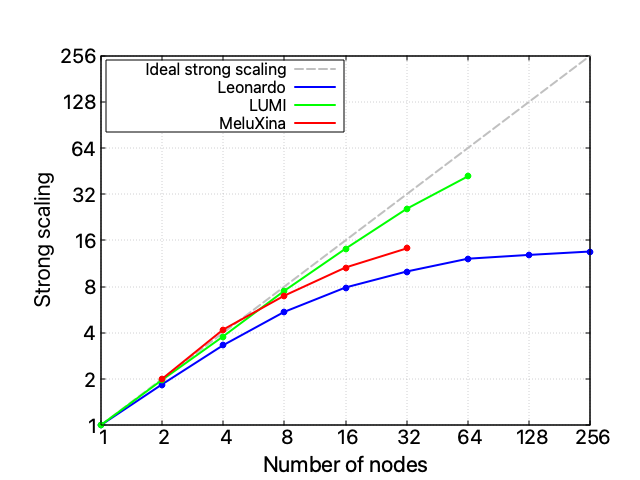
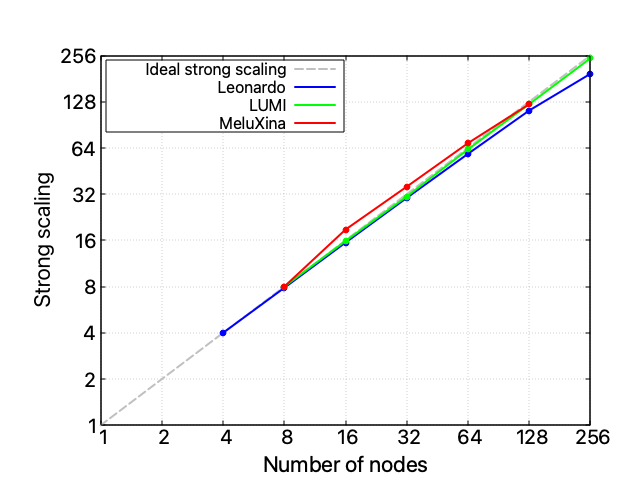
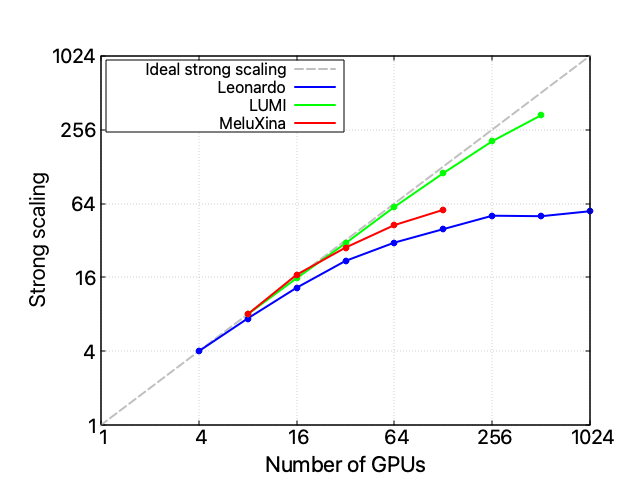
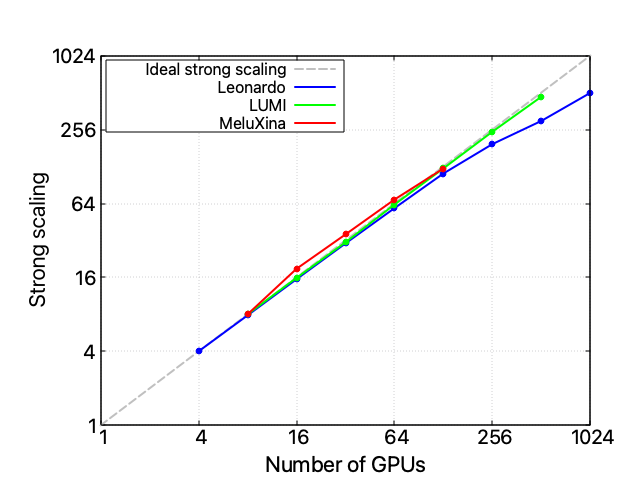
However, despite the similar scaling profile, the three HPC infrastructures expose radically different absolute computational times.
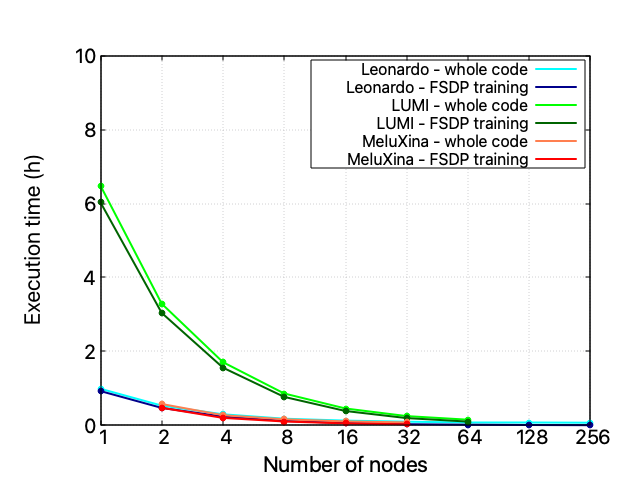
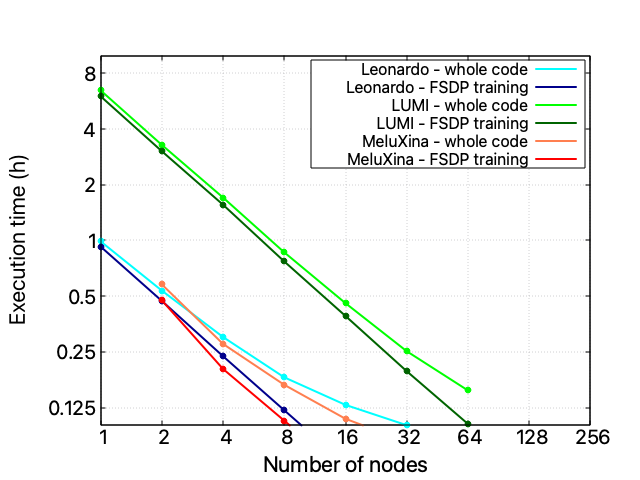
Multi HPC execution
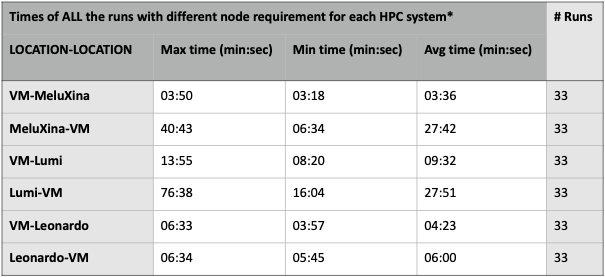
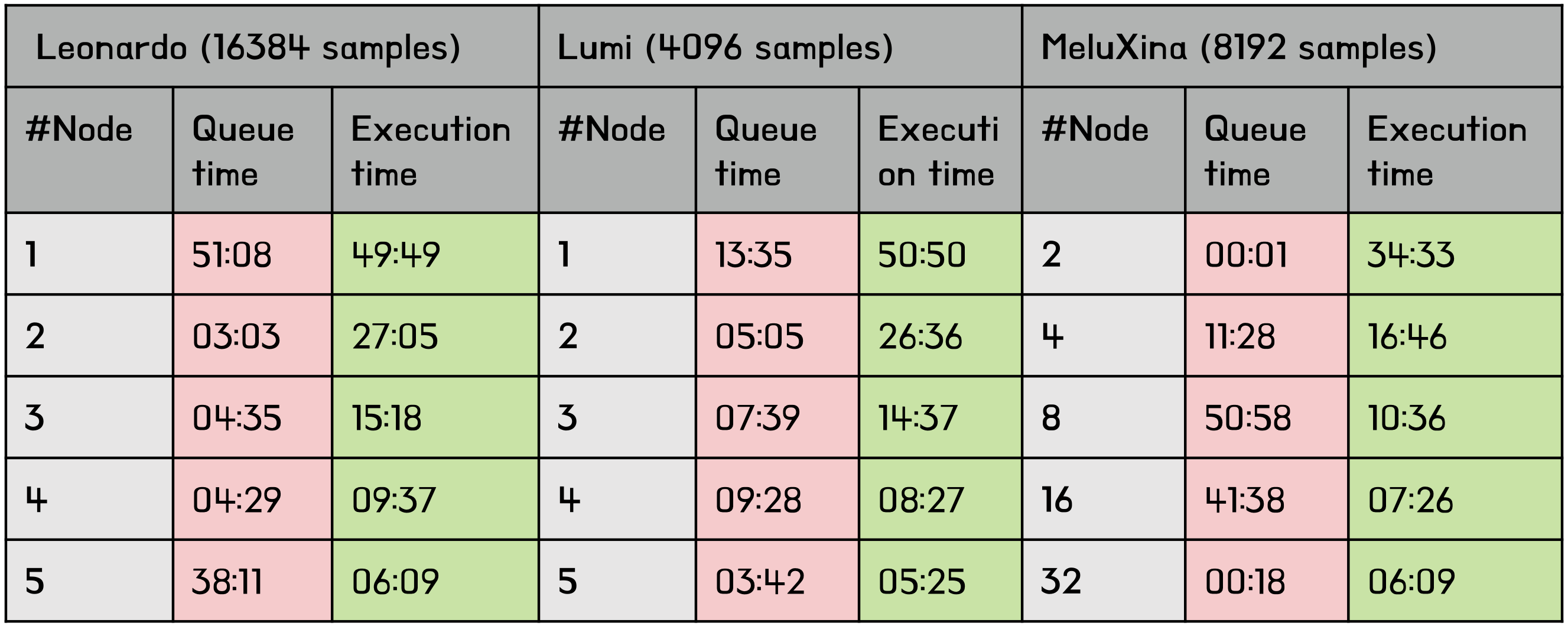
Many xFFL experiments are launched to train LLaMA-3 8B (15 GB disk size, half-precision) on 28672 samples from the clean_mc4_it dataset. The base configuration is 1 Leonardo node, 1 LUMI node, and 2 MeluXina nodes (a single LLaMA-3 8B instance won’t fit into a single MeluXina node), with the data split according to each facility’s computing power to balance the execution times.
Queue times expose an extremely variable behaviour due to dense periods with high workload in the systems (e.g., before the SC deadline or after an extended maintenance period). Data have been collected on a small set of runs: a more extensive data collection on a larger amount of time is required for proper evaluation. Queue-aware scheduling policies that adjust workloads based on predicted queue times should be investigated to reduce the impact of outliers
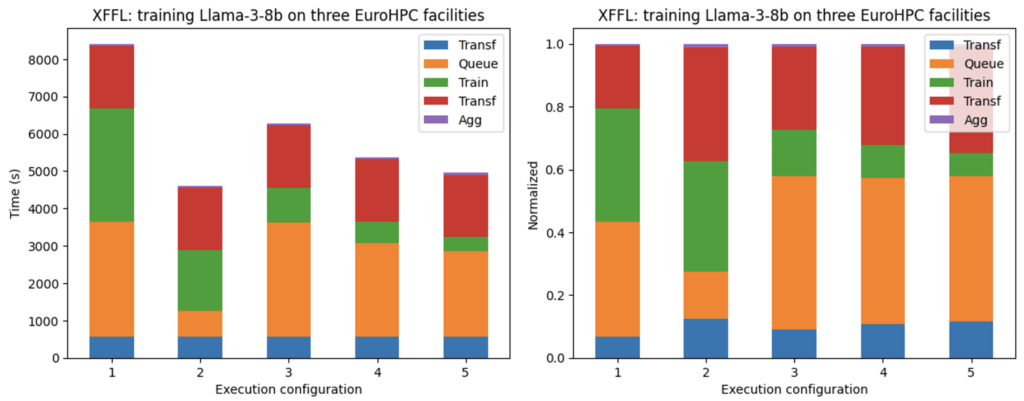
Conclusions
What we learnt:
- LLM traning workflows scaledifferently on different HPC facilities
- This is mainly due to overhead handling (model loading, PyTorch distributed setup)
- FSDP-training scales well up to 128 nodes on all HPC facilities, but with very different compute times26
What we plan to do:
- Carefully balancing data betweendifferent HPC facilities to obtainhomogeneous times for each round
- Reduce model loading time byusing high-end storage and I/O optimisation techniques (e.g., GPUDirect storage)
- Investigate strategies to avoid PyTorch cold restarts on all nodes (caching, faster setup algorithms)
- Investigate computing and communication bottlenecks at large scales
Is XFFL Ready for Production Workloads? NO
- Significant overhead: model loading and PyTorch distributed setup become significant at large scale, and queuing times expose an extreme variability
- Scalability limits: single-facility scalability for LLM training workloads is capped to 128/256 nodes, which prevents efficient full-facility usages
- Reparametrisation needed: large-scale training processes require different hyperparameter values to preserve accuracy, but further studies are ongoing
- HPC instability: node failures, network instabilities, and frequent maintenance periods made it difficult to use three facilities at the same time
- Extreme heterogeneity: different machines come with different interfaces, HPC structure, computing hours allocation policies, computing time accounting (node hours vs GPU hours vs core hours), and so on
- Container support: no standard way to build Singularity containers on the systems (it is not even allowed in some facilities)
Is XFFL Still Promising for Large-Scale AI? YES
- Queue times are unavoidable: HPC facilities limit the time a single job can run. If each round lasts the maximum amount of job time, queue times are the same for XFFL and the standard training
- Better load balance: if many HPC facilities are available, training jobs can be submitted to less congested ones, reducing queue time
- Less communications: as long as training jobs does not scale above 128/256 nodes, running multiple models in parallel and aggregating them can improve scalability
Future works
- What is the maximum round duration? Aggregating too often kills performance, but aggregating too rarely kills accuracy. Which is the best trade-off?
- What about MoEs? Many modern large-scale AI models are Mixtures of Experts. Does FL work well with these kinds of models?
Authors
Gianluca Mittone, Alberto Mulone, Giulio Malenza, Robert Birke, Iacopo Colonnelli, Marco Aldinucci – Parallel Computing [ALPHA] research group, University of Torino, Torino, Italy
Contributors
Data resources: Valerio Basile, Marco Antonio Stranisci, Viviana Patti – University of Torino, Torino, Italy
Access to Leonardo supercomputer: Sanzio Bassini, Gabriella Scipione, Massimiliano Guarrasi – CINECA, Italy
Access to Carolina supercomputer: Jan Martinovic, Vit Vondrak – IT4AI, Czech Republic
References
- I. Colonnelli, B. Casella, G. Mittone, Y. Arfat, B. Cantalupo, R. Esposito, A. R. Martinelli, D. Medić, and M. Aldinucci, “Federated Learning meets HPC and cloud,” in Astrophysics and Space Science Proceedings, Catania, Italy, 2023, p. 193–199. doi:10.1007/978-3-031-34167-0_39 [Download PDF]
- G. Mittone, W. Riviera, I. Colonnelli, R. Birke, and M. Aldinucci, “Model-Agnostic Federated Learning,” in Euro-Par 2023: Parallel Processing, Limassol, Cyprus, 2023. doi:10.1007/978-3-031-39698-4_26 [Download PDF]
- G. Mittone, N. Tonci, R. Birke, I. Colonnelli, D. Medić, A. Bartolini, R. Esposito, E. Parisi, F. Beneventi, M. Polato, M. Torquati, L. Benini, M. Aldinucci, “Experimenting with Emerging RISC-V Systems for Decentralised Machine Learning,” in 20th ACM International Conference on Computing Frontiers (CF ’23), ACM, Bologna, Italy, 2023. doi:10.1145/3587135.3592211 [Download PDF]
- I. Colonnelli, B. Cantalupo, I. Merelli, and M. Aldinucci, “StreamFlow: cross-breeding cloud with HPC,” IEEE Transactions on Emerging Topics in Computing, vol. 9, iss. 4, p. 1723–1737, 2021. doi:10.1109/TETC.2020.3019202 [Download PDF]
- Colonnelli, B. Cantalupo, R. Esposito, M. Pennisi, C. Spampinato, and M. Aldinucci, “HPC Application Cloudification: The StreamFlow Toolkit,” in 12th Workshop on Parallel Programming and Run-Time Management Techniques for Many-core Architectures and 10th Workshop on Design Tools and Architectures for Multicore Embedded Computing Platforms (PARMA-DITAM 2021), Dagstuhl, Germany, 2021, p. 5:1–5:13. doi:10.4230/OASIcs.PARMA-DITAM.2021.5 [Download PDF]
- M. Aldinucci, E. M. Baralis, V. Cardellini, I. Colonnelli, M. Danelutto, S. Decherchi, G. D. Modica, L. Ferrucci, M. Gribaudo, F. Iannone, M. Lapegna, D. Medic, G. Muscianisi, F. Righetti, E. Sciacca, N. Tonellotto, M. Tortonesi, P. Trunfio, and T. Vardanega, “A Systematic Mapping Study of Italian Research on Workflows,” in Proceedings of the SC ’23 Workshops of The International Conference on High-Performance Computing, Network, Storage, and Analysis, SC-W 2023, Denver, CO, USA, 2023, p. 2065–2076. doi:10.1145/3624062.3624285 [Download PDF]
- Meta AI, “Introducing LLaMA: A foundational, 65-billion-parameter large language model,” last accessed Dec 2023, https://ai.meta.com/blog/large-language-model-llama-meta-ai/
- H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhar- gava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V. Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V. Kerkez, M. Khabsa, I. Kloumann, A. Korenev, P. S. Koura, M.-A. Lachaux, T. Lavril, J. Lee, D. Liskovich, Y. Lu, Y. Mao, X. Martinet, T. Mihaylov, P. Mishra, I. Molybog, Y. Nie, A. Poul- ton, J. Reizenstein, R. Rungta, K. Saladi, A. Schelten, R. Silva, E. M. Smith, R. Subramanian, X. E. Tan, B. Tang, R. Taylor, A. Williams, J. X. Kuan, P. Xu, Z. Yan, I. Zarov, Y. Zhang, A. Fan, M. Kambadur, S. Narang, A. Rodriguez, R. Stojnic, S. Edunov, and T. Scialom, “LLaMA 2: Open foundation and fine-tuned chat models,” arXiv:2307.09288, 2023. [Download PDF]
- I. Colonnelli, R. Birke, G. Malenza, G. Mittone, A. Mulone, J. Galjaard, L. Y. Chen, S. Bassini, G. Scipione, J. Martinovič, V. Vondrák, M. Aldinucci, “Cross-Facility Federated Learning,” in Procedia Computer Science, vol. 240, p. 3-12, 2024. doi:10.1016/j.procs.2024.07.003 [Download PDF]
- M. Pennisi, F. Proietto Salanitri, G. Bellitto, B. Casella, M. Aldinucci, S. Palazzo, and C. Spampinato, “FedER: Federated Learning through Experience Replay and Privacy-Preserving Data Synthesis,” Computer Vision and Image Understanding, 2023. doi:10.1016/j.cviu.2023.103882 [Download PDF]










